redux-observable 사용하기
redux-observable은 RxJS로 Redux에서 비동기 액션을 처리할 수 있게 해줍니다.
기초
액션을 Observable로 다루기
redux-observable에서는 Redux 스토어에 들어오는 액션들을 Observable로 다룰 수 있게 해줍니다. dispatch가 호출되면, 액션이 스토어에서 처리된 후에 Observable에 액션이 출력됩니다.
실제로는 Observable을 확장한 ActionsObservable을 얻을 수 있는데 여기에는 특정 종류의 액션만 걸러낼 수 있는 ofType 연산자가 추가로 제공됩니��다. .ofType('ACTION_TYPE')은 .filter(action => action.type === 'ACTION_TYPE')와 동일합니다.
Epic
redux-observable에서는 액션이 들어오는 이벤트를 받아서 추가적인 액션을 발생시킬 수 있습니다. (이미 들어온 액션을 바꾸거나 없앨 수는 없습니다.) 이렇게 액션의 Observable을 추가로 발생시킬 액션의 Observable로 바꿔주는 함수를 Epic이라고 부릅니다. 그림으로 보면 다음과 같습니다.
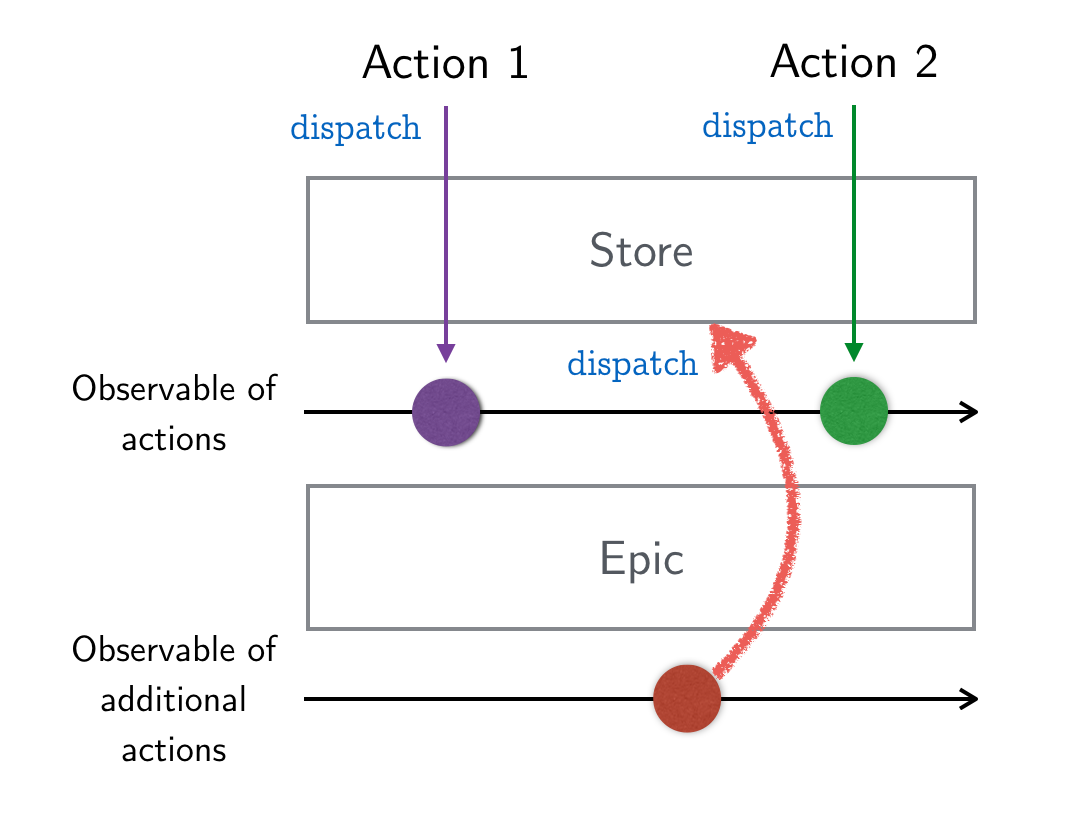
Epic은 '서사시'라는 뜻인데 Epic이 실행되는 동안 발생하는 액션을 어떻게 처리할지에 대한 이야기이기 때문에 그런 이름이 된 것이 아닐까 생각합니다.
PING 액션을 받아서 PONG 액션을 발생시키는 가장 간단한 Epic을 생각해볼 수 있습니다. (별로 쓸모는 없지만)
function pingEpic(action$) {
return action$.ofType('PING')
.map(action => ({ type: 'PONG' }));
}
실제로도 유용할 것 같은, 액션을 받아서 비동기 API를 호출하고 성공 액션을 발생시키는 가장 기본적인 Epic은 다음과 같이 생겼습니다.
function fetchPostsEpic(action$) {
return action$.ofType('FETCH_POSTS')
.mergeMap(action =>
getPosts()
.map(posts => ({ type: 'FETCH_POSTS_SUCCESS', payload: posts }))
.catch(err => Observable.of({
type: 'FETCH_POSTS_ERROR', payload: err, error: true
}))
);
}
리듀서는 이런 식으로 만들 수 있을겁니다.
function reducer(state = {}, action) {
switch (action.type) {
case 'FETCH_POSTS':
// Epic과 무관하게 FETCH_POSTS는 리듀서로 들어옵니다!
return { isLoading: true };
case 'FETCH_POSTS_SUCCESS':
return { isLoading: false, posts: action.payload };
case 'FETCH_POSTS_ERROR':
return { isLoading: false, error: action.payload };
default:
return state;
}
}
여러 Epic 합성하기
일반적으로 처리하는 액션 타입에 따라 여러 개의 Epic을 만들어서 합성하여 사용하게 됩니다. 합성은 combineEpics 함수를 사용하고, 이렇게 합쳐져서 최종적으로 만들어진 Epic을 Root Epic이라고 합니다. (리듀서를 combineReducers로 합쳐서 루트 리듀서를 만드는 것과 비슷합니다)
import { combineEpics } from 'redux-observable';
const rootEpic = combineEpics(
pingEpic,
fetchPostsEpic,
);
적용
의존성 설치
npm으로 rxjs와 redux-observable을 설치합니다.
Epic Middleware 추가하기
Epic을 실제로 적용하려면 미들웨어를 통해서 Redux 스토어에 붙입니다.
import { createStore, applyMiddleware } from 'redux';
import { createEpicMiddleware } from 'redux-observable';
const epicMiddleware = createEpicMiddleware(rootEpic);
const store = createStore(
rootReducer,
applyMiddleware(
epicMiddleware,
...
)
);
실전 팁
프로젝트 구조
공식 문서에서는 Ducks 패턴을 추천하고 있습니다. Ducks 패턴은 연관된 액션 타입, 액션 크리에이터와 리듀서를 하나의 모듈로 묶는 방식인데 여기에 Epic이 추가되는 겁니다.
Epic에서 스토어 상태 가져오기
사실 Epic의 두번째 파라미터로는 Redux 스토어가 들어옵니다. 따라서 필요할 때 getState()를 호출하여 스토어 상태에 따라 액션을 처리할 수 있습니다.
function addCommentEpic(action$, store) {
return action$.ofType('ADD_COMMENT')
.mergeMap(action => {
const { currentUser } = store.getState();
return addComment(currentUser, action.body)
.map(...);
})
}
비동기 요청 취소하기
RxJS의 takeUntil 연산자를 적용하면 특정 액션이 들어올 때 동작을 취소할 수 있습니다.
function fetchPostsEpic(action$) {
return action$.ofType('FETCH_POSTS')
.mergeMap(action =>
getPosts()
.map(posts => ({ type: 'FETCH_POSTS_SUCCESS', payload: posts }))
// FETCH_POSTS_CANCEL 액션이 들어오면 구독 취소
.takeUntil(action$.ofType('FETCH_POSTS_CANCEL'))
);
}
액션 종료 시에 알림 받기
Epic의 구조상 액션을 dispatch하는 곳에서 액션 처리가 완료된 것을 알기 어렵습니다. 모든 것을 Redux에서 관리하는 것이 최선이긴 하지만 때로는 탈출구가 필요하기도 합니다.
어쩔 수 없을 때는 redux-observable에 올라온 이슈에서 힌트를 얻어서 액션에 콜백을 같이 넘기는 방법을 사용해볼 수 있습니다. (콜백보다는 Promise나 RxJS의 Subject를 사용하면 약간 더 깔끔합니다.)
function fetchPostsEpic(action$) {
return action$.ofType('FETCH_POSTS')
.mergeMap(action =>
getPosts()
.do(posts => {
if (action.meta.callback)
action.meta.callback(posts); // 밖에 알려주기
})
.map(posts => ({ type: 'FETCH_POSTS_SUCCESS', payload: posts }))
);
}
dispatch({
type: 'FETCH_POSTS',
meta: { callback: () => console.log('done!') }
});