Thinking in GraphQL (번역)
(이 글은 Relay 문서 중 Thinking in GraphQL 장을 번역한 것입니다. 245df1e0 리비전을 기준으로 하고 있으며, 저장소의 라이센스를 따라 BSD 라이센스입니다. 원작자의 허락으로 별도로 받지는 않았음을 밝힙니다.)
GraphQL은 클라이언트에서 데이터를 가져오는 새로운 방식을 제시합니다. 제품 개발자와 클라이언트 애플리케이션의 요구사항에 중점을 둔 방식입니다. 뷰에서 정확히 어떤 데이터가 필요한지 명시할 수 있는 방법을 제공하며, 클라이언트는 필요한 데이터를 단 한번의 네트워크 요청으로 가져올 수 있습니다. GraphQL을 사용하면 REST 등 기존 접근 방식에 비해 애플리케이션이 데이터를 더욱 효율적으로(리소스 중심 REST 방식 대비) 가져올 수 있고 (커스텀 엔드포인트를 만들 때 발생할 수 있는) 서버 로직의 중복을 줄일 수 있습니다. 그에 더해 GraphQL은 제품 코드와 서버 로직의 결합도를 낮추는 데 도움을 줍니다. 예를 들어 제품에서 필요한 정보가 많아지거나 적어질 때 서버의 관련 엔드포인트를 모두 수정하지 않아도 됩니다. It's a great way to fetch data.
이 글에서는 GraphQL 클라이언트 프레임워크를 만든다는 것의 의미를 알아보고, 그것이 기존의 REST 시스템을 위한 클라이언트와 어떻게 다른지 비교해볼 것입니다. 그 과정에서 Relay의 설계 결정사항에 어떤 배경이 있는지 살펴보며 Relay가 단지 GraphQL 클라이언트일 뿐만 아니라 선언적으로 데이터를 가져올 수 있는 프레임워크임을 보여드리겠습니다. 자, 이제 데이터를 가져오기 시작해볼까요!
데이터 가져오기
스토리의 목록과 각 스토리의 상세 정보를 가져오는 간단한 애플리케이션을 생각해봅시다. 리소스 중심 REST 방식에서는 다음과 같을 것입니다.
// 스토리 ID 목록을 가져온다. 단, 상세 정보는 가져오지 않음.
rest.get('/stories').then(stories =>
// 결과값은 연결된 리소스의 목록
// `[ { href: "http://.../story/1" }, ... ]`
Promise.all(stories.map(story =>
rest.get(story.href) // 링크 따라가기
))
).then(stories => {
// 결과값은 스토리의 목록
// `[ { id: "...", text: "..." } ]`
console.log(stories);
});
이렇게 하면 서버에 n+1개의 요청을 보내야 합니다. 리스트를 가져올 때 1번, 각 항목을 가져올 때 n번. GraphQL에서는 같은 데이터를 단 하나의 네트워크 요청으로 가져올 수 있습니다. (별도의 엔드포인트를 만들지 ��않고 가능합니다. 만약 만든다면 계속 관리해야겠지요)
graphql.get('query { stories { id, text } }').then(
stories => {
// 스토리의 목록
// `[ { id: "...", text: "..." } ]`
console.log(stories);
}
);
여기까지는 GraphQL을 그저 일반적인 REST 방식의 효율적인 버전으로만 사용했습니다. GraphQL 버전의 중요한 장점 두가지를 알 수 있습니다.
- 모든 데이터를 한번의 라운드트립으로 가져올 수 있습니다.
- 클라이언트와 서버가 서로 독립적입니다. 서버 엔드포인트가 정확한 데이터를 돌려주는 것에 의존하는 대신 클라이언트가 필요한 데이터를 명시합니다.
간단한 애플리케이션에서는 이미 이것만으로도 큰 개선일 것입니다.
클라이언트측 캐싱
서버로부터 같은 정보를 반복해서 읽어오면 느릴 수 있습니다. 예를 들어 스토리 목록에서 하나의 항목으로 갔다가 다시 목록으로 돌아온다고 하면, 전체 목록을 다시 가져와야 합니다. 일반적으로 쓰이는 방법인 캐싱으로 이러한 문제를 해결해 보겠습니다.
리소스 중심 REST 시스템에서는 URI에 기반한 응답 캐시를 관리할 수 있습니다.
var _cache = new Map();
rest.get = uri => {
if (!_cache.has(uri)) {
_cache.set(uri, fetch(uri));
}
return _cache.get(uri);
};
응답 캐싱 방식은 GraphQL에도 적용됩니다. 기초적인 방법은 REST 버전과 비슷하게 작동할 것입니다. 쿼리 문자열 자체를 캐시 키로 사용할 수 있습니다.
var _cache = new Map();
graphql.get = queryText => {
if (!_cache.has(queryText)) {
_cache.set(queryText, fetchGraphQL(queryText));
}
return _cache.get(queryText);
};
이제 이전에 캐시된 데이터를 요청하면 네트워크 요청 없이도 바로 답을 받을 수 있습니다. 이는 애플리케이션의 체감 성능을 향상시키는 실용적인 접근법입니다. 그러나 이러한 방식은 데이터 일관성 문제를 일으킬 수 있습니다.
캐시의 일관성
GraphQL에서는 여러 쿼리의 결과가 겹치는 경우가 자주 있습니다. 그런데 위에서 사용한 응답 캐시는 이렇게 결과가 겹치는 성질을 고려하지 않고 개별 쿼리에 대해서만 캐싱합니다. 예를 들어 다음과 같이 스토리를 가져오는 쿼리를 날리고,
query { stories { id, text, likeCount } }
가져온 스토리 중 하나의 likeCount가 증가한 이후에 다시 가져오면
query { story(id: "123") { id, text, likeCount } }
이제 스토리가 어떤 방법으로 접근되는지에 따라 다른 likeCount를 보게 될 것입니다. 첫번째 쿼리를 사용하는 뷰는 오래된 카운트를 사용하는데 두번째 쿼리는 업데이트된 카운트를 표시합니다.
그래프를 캐시하기
GraphQL에 적합한 캐시 방식은 계층 구조의 응답을 단일 계층의 레코드 집합으로 정규화하는 것입니다. Relay에서는 ID에 대응되는 레코드의 map 자료구조로 이러한 방식의 캐시를 구현하였습니다. 각 레코드는 필드명에 대응되는 필드 값의 map입니다. 레코드는 다른 레코드와 연결될 수 있고 링크는 최상위 계층의 map을 참조하는 특별한 타입의 값으로 저장됩니다. (따라서 순환 그래프도 표현할 수 있습니다.) 이렇게 하여 각 서버상의 레코드는 가져오는 방법에 무관하게 한번만 저장됩니다.
다음은 스토리의 글과 작성자 이름을 가져오는 예제 쿼리입니다.
query {
story(id: "1") {
text,
author {
name
}
}
}
그리고 다음과 같은 응답을 받을 수 있습니다.
query: {
story: {
text: "Relay is open-source!",
author: {
name: "Jan"
}
}
}
응답은 계층 구조로 되어있지만, 모든 레코드를 단일 계층으로 만들어 캐시할 것입니다. 다음은 Relay가 이 응답을 캐시하는 예입니다.
Map {
// `story(id: "1")`
1: Map {
text: 'Relay is open-source!',
author: Link(2),
},
// `story.author`
2: Map {
name: 'Jan',
},
};
이것은 단순화한 예제에 불과합니다. 실제로는 일대다 관계와 페이지 관리 등도 캐시에서 처리할 수 있어야 합니다.
캐시 사용하기
그러면 이제 이 캐시를 어떻게 사용할 수 있을까요? 응답을 받았을 때 캐시에 쓰는 것과, 캐시를 읽어 쿼리가 로컬에서 완전히 처리될 수 있는지 판단하는 두가지 작업을 살펴봅시다. (위에서 사용한 _cache.has(key)와 같지만 그래프를 위한 것입니다)
캐시 추가하기
캐시를 추가하려면 계층 구조의 GraphQL 응답을 순회하면서 정규화된 캐시 레코드를 만들거나 업데이트하게 됩니다. 처음엔 응답 그 자체만 있으면 충분히 응답을 처리할 수 있을 것처럼 보이지만 실제로는 단순한 쿼리에서만 가능합니다. user(id: "456") { photo(size: 32) { uri } }라는 쿼리를 생각해보면, photo를 어떻게 저장해야 할까요? photo를 캐시의 필드명으로 사용하면 다른 쿼리에서 같은 필드를 다른 인자값으로 가져올 수도 있으므로 (예: photo(size: 64) {...}) 안됩니다. 비슷한 문제가 페이지를 나누는 경우에도 발생합니다. 만약 11번째부터 20번째까지의 스토리를 stories(first: 10, offset: 10)로 가져온다면 새로운 결과는 기존 목록에 덧붙여져야 합니다.
따라서, GraphQL을 위한 정규화된 응답 캐시는 응답 페이로드와 쿼리를 동시에 처리해야만 합니다. 예를 들어 위에서 예로 든 photo 필드는 photo_size(32)처럼 자동 생성된 필드명으로 캐시하면 필드와 인자값을 유일하게 구별할 수 있을 것입니다.
캐시에서 읽기
캐시에서 읽어오려면 쿼리를 순회하면서 각 필드를 처리해야 합니다. 잠깐, 이거 GraphQL이 하��는 일과 정확히 같은거 아닌가요? 그렇습니다! 캐시에서 읽어오는 작업은 실행기의 특수한 케이스입니다. 첫째, 모든 결과값이 고정된 자료 구조에서 오므로 사용자 정의 필드 함수가 필요하지 않습니다. 둘째, 결과값은 항상 동기적입니다 — 캐시된 데이터가 존재하거나, 또는 없거나.
Relay에는 조금씩 다른 여러 종류의 **쿼리 순회(traversal)**가 구현되어 있습니다. 캐시나 응답 페이로드 등 다른 데이터와 동시에 쿼리를 순회하는 작업입니다. 예를 들어 쿼리할 때는 "diff" 순회를 돌면서 어떤 필드가 없는지 찾습니다. (React에서 가상 DOM 트리를 비교하는 것과 비슷합니다.) 이렇게 하면 대부분의 경우 가져올 데이터의 양을 줄일 수 있고 쿼리 전체가 캐시되어 있을 때는 네트워크 요청을 아예 하지 않아도 됩니다.
캐시 업데이트
이렇게 정규화된 캐시 구조는 겹치는 결과를 중복 없이 캐시할 수 있게 해줍니다. 각 레코드는 가져온 방법에 관계 없이 한번만 저장됩니다. 앞의 일관성 없는 데이터 예제로 돌아가서 이 캐시가 그러한 시나리오에서 어떤 도움을 주는지 살펴봅시다.
첫번째 쿼리는 스토리의 목록이었습니다.
query { stories { id, text, likeCount } }
정규화된 응답 캐시에서는, 목록의 각 스토리에 대한 레코드가 만들어지고 stories 필드는 각 레코드에 대한 링크를 담을 것입니다.
위의 스토리 중 하나의 정보를 다시 가져오는 두번째 쿼리는 다음과 같았습니다.
query { story(id: "123") { id, text, likeCount } }
이 쿼리의 응답이 정규화될 때, Relay는 id를 가지고 결과값이 기존 데이터와 겹친다는 것을 알아낼 수 있습니다. 새로운 레코드를 만드는 대신 기존의 123 레코드가 업데이트될 것입니다. 따라서 새로운 likeCount는 두 쿼리 모두와 이 스토리를 참조하는 다른 모든 쿼리에 적용됩니다.
데이터-뷰 일관성
정규화된 캐시는 캐시의 일관성을 보장합니다. 그렇다면 뷰에 대해서는 어떨까요? React 뷰가 항상 캐시의 현재 정보를 반영하는 것이 이상적일겁니다.
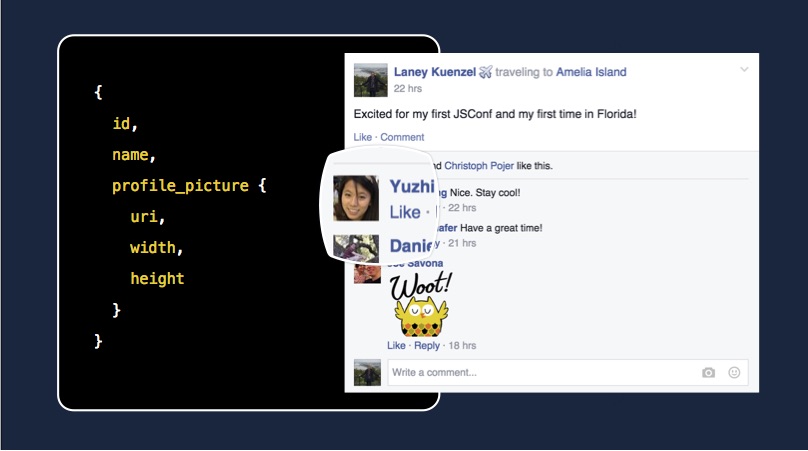
스토리의 글과 댓글을 작성자 이름 및 사진과 함께 표시하는 경우를 생각해봅시다. GraphQL 쿼리는 다음과 같습니다.
query {
node(id: "1") {
text,
author { name, photo },
comments {
text,
author { name, photo }
}
}
}
처음 이 스토리를 가져오면 캐시는 다음과 같이 됩니다. 스토리와 댓글이 같은 author 레코드에 연결되어 있는 것을 확인할 수 있습니다.
// 참고: 구조를 명확하게 알 수 있도록 `Map`을 초기화할 때 슈도코드를 사용함
Map {
// `story(id: "1")`
1: Map {
author: Link(2),
comments: [Link(3)],
},
// `story.author`
2: Map {
name: 'Yuzhi',
photo: 'http://.../photo1.jpg',
},
// `story.comments[0]`
3: Map {
author: Link(2),
},
}
이 스토리의 작성자가 같은 스토리에 댓글도 달았습니다. 흔한 일이죠. 이제 다른 뷰가 작성자에 대한 새로운 정보를 가져와서 프로필 사진이 새로운 URI로 바뀌는 경우를 생각해보겠습니다. 다음 부분이 유일하게 캐시된 데이터에서 바뀔 것입니다.
Map {
...
2: Map {
...
photo: 'http://.../photo2.jpg',
},
}
photo 필드의 값이 변경됐으므로 레코드 2 또한 바뀌었습니다. 그리고 그게 전부입니다. 캐시의 다른 부분은 영향을 받지 않았습니다. 하지만 분명히 새로운 사진을 보여주려면 뷰는 작성자에 대한 UI 상의 인스턴스 두 개(스토리의 작성자, 댓글의 작성자)에 변경 사항을 반영해야 합니다.
이럴 때 일반적인 반응은 "그냥 불변(immutable) 데이터 구조를 쓰면 되겠지"입니다. 하지만 그렇게 하면 무슨 일이 일어날까요?
ImmutableMap {
1: ImmutableMap {/* 이전과 같음 */}
2: ImmutableMap {
... // 다른 필드는 그대로
photo: 'http://.../photo2.jpg',
},
3: ImmutableMap {/* 이전과 같음 */}
}
2를 새로운 불변 레코드로 바꾸면 캐시 객체의 새로운 불변 인스턴스가 만들어집니다. 그러나 1, 3 레코드는 그대로입니다. 데이터가 정규화되어 있기 때문에 story 레코드 하나만 봐서는 story의 내용이 바뀌었는지 알 수 없습니다.
뷰의 일관성을 유지하기
단일 계층의 캐시에서 뷰를 최신으로 유지하는 방법은 여러가지입니다. Relay에서는 각 UI 뷰와 뷰에서 참조하고 있는 ID 간의 매핑을 관리하는 방식을 선택했습니다. 이 경우 스토리 뷰는 스토리(1), 작성자(2), 댓글들(3, ...)의 업데이트를 구독하게 됩니다. 데이터를 캐시에 쓸때 영향을 받은 ID를 추적하여 그 ID들을 구독하고 있는 뷰에만 알려줍니다. 영향을 받은 뷰가 다시 렌더링되고 관계 없는 뷰는 제외되어 더 나은 성능을 냅니다. (Relay는 안전하면서도 효과적인 shouldComponentUpdate의 기본값을 제공합니다.) 이러한 전략을 사용하지 않으면 작은 변화만으로도 모든 뷰를 새로 렌더링해야 할 것입니다.
참고로 이 방법은 쓰기에도 마찬가지로 적용할 수 있습니다. 캐시가 업데이트되면 영향을 받는 뷰가 통지를 받게 되는데, �쓰기 또한 그저 캐시를 업데이트하는 일이기 때문입니다.
뮤테이션
지금까지 데이터를 쿼리하고 뷰를 최신으로 유지하는 과정을 살펴보았는데 아직 쓰기에 대해서는 이야기하지 않았습니다. GraphQL에서는 쓰기를 **뮤테이션(mutation)**이라고 부릅니다. 사이드 이펙트가 있는 쿼리라고 생각하시면 됩니다. 다음은 현재 유저가 주어진 스토리를 좋아요 표시하는 뮤테이션의 예입니다.
// 사람이 읽을 수 있는 이름을 붙이고 입력값의 타입을 정의
// 여기서는 좋아요 표시할 스토리의 id
mutation StoryLike($storyID: String) {
// 뮤테이션 필드를 호출하고 사이드 이펙트를 발생시킴
storyLike(storyID: $storyID) {
// 뮤테이션이 끝나고 다시 가져올 필드를 정의
likeCount
}
}
뮤테이션의 결과로 바뀔수도 있는 데이터를 쿼리하고 있습니다. 왜 서버가 그냥 무엇이 바뀌었는지 알려줄 수 없나요?라고 생각하실 수 있습니다. 그 이유는, 복잡해서 그렇습니다. GraphQL은 임의의 데이터 저장 레이어(또는 여러 소스의 모음)을 추상화하며 프로그래밍 언어 독립적입니다. 더군다나 GraphQL의 목표는 뷰를 만드는 제품 개발자에게 유용한 형태로 데이터를 제공하는 것입니다.
저희는 GraphQL 스키마가 디스크에 데이터가 저장되는 형태와 약간 차이가 있거나 심지어 완전히 다르다는 것을 알게 되었습니다. 간단히 말해, 하위 계층의 데이터 스토리지(디스크)에서 바뀌는 데이터와 제품에서 보는 스키마(GraphQL)가 항상 1:1로 대응되지는 않는다는 것입니다. 개인정보 공개 설정이 적절한 예입니다. 나이처럼 유저에게 보이는 필드 하나를 알려주기 위해서도, 데이터 저장 레이어에서는 현재 유저가 그 값을 볼 수 있는지 판단하려면 엄청나게 많은 기록을 살펴봐야 할 수 있습니다. (그 사람�과 친구인지? 나이를 공유했는지? 차단한 적이 있는지 등등)
이렇듯 현실적인 제약 때문에 GraphQL에서는 클라이언트가 뮤테이션 후에 바뀔 수도 있는 것들을 쿼리하도록 하고 있습니다. 그렇다면 그 쿼리에는 무엇이 들어가야 하는가? Relay를 개발하면서 여러가지 아이디어를 시도해 보았는데 간단히 살펴보고 왜 현재 방식을 선택했는지 알아봅시다.
-
방법 1: 지금까지 앱에서 쿼리한 모든 것을 다시 가져오기. 실제로는 전체 데이터 중 아주 일부분만 바뀌더라도 서버가 전체 쿼리를 실행하고 결과를 다운로드하고 처리가 끝날 때까지 기다려야 하므로 비효율적입니다.
-
방법 2: 현재 렌더링된 뷰에서 필요한 쿼리만 다시 가져오기. 방법 1의 개선판입니다. 그러나 캐시되어 있지만 지금 보이지 않는 데이터는 갱신되지 않습니다. 이런 데이터를 낡은 것으로 표시하거나 캐시에서 없앨 방법이 있지 않다면 이후의 쿼리는 오래된 정보를 읽게 됩니다.
-
방법 3: 뮤테이션 이후에 바뀔수도 있는 필드의 고정된 리스트를 다시 가져오기. 이런 리스트를 팻(fat) 쿼리라고 부릅니다. 일반적인 애플리케이션은 팻 쿼리의 일부분만 렌더링하는데, 이 방법으로는 명시된 모든 필드를 가져와야 하므로 비효율적일 수 있습니다.
-
방법 4 (Relay): 바뀔 수도 있는 것(팻 쿼리)와 캐시에 있는 데이터의 교집합을 다시 가져오기. Relay에서는 데이터 캐시와 함께 각 항목을 가져오기 위해 사용된 쿼리도 기억하고 있습니다. 이러한 쿼리는 추적(tracked) 쿼리라고 합니다. 추적 쿼리와 팻 쿼리에서 겹치는 부분을 찾으면 애플리케이션에서 업데이트해야 하는 정보만 정확히 쿼리할 수 있습니다.
데이터 가져오기 API
이제까지 데이터 가져오기의 저수준 측면을 살펴보고 어떻게 여러가지 친숙한 개념이 GraphQL로 변환될 수 있는지 보았습니다. 다음으로 한발짝 물러나 제품 개발자들이 데이터 가져오기와 관련하여 자주 마주치는 고수준의 문제를 짚어보겠습니다.
- 뷰 계층에서 필요한 모든 데이터 가져오기
- 비동기 상태 전환을 관리하고 동시적인 요청을 조정
- 에러 관리
- 실패한 요청 재시도
- 쿼리/뮤테이션 응답으로부터 로컬 캐시 업데이트
- 뮤테이션을 큐에 쌓아 레이스 컨디션 방지
- 서버의 뮤테이션 응답을 기다리는 동안 낙관적으로(optimistically) UI 업데이트
명령형(imperative) API를 사용한 일반적인 접근 방법으로는 개발자들이 이처럼 핵심과는 무관한 복잡함을 다룰 수 밖에 없습니다. 예를 들어 낙관적인 UI 업데이트를 생각해보겠습니다. 서버의 응답을 기다리는 동안 사용자에게 피드백을 줄 수 있는 방법입니다. 무엇을 해야 하는가에 대한 로직은 꽤나 분명합니다. 사용자가 "좋아요"를 누르면, 스토리를 좋아요 표시한 것으로 만들고 서버에 요청을 보내면 됩니다. 하지만 실제로 구현하는건 훨씬 복잡한 경우가 많습니다. 명령형 방식에서는 우리가 이 모든 과정을 구현해야 합니다. UI에 가서 버튼을 켜진 상태로 만들고, 네트워크 요청을 시작하고, 필요하면 재시도를 하고, 실패하면 요청을 보내고(그리고 버튼을 다��시 끄고), 등등. 데이터 가져오기도 마찬가지입니다. 어떤 데이터가 필요한지를 명시하는 것이 거의 항상 어떻게 그리고 언제 그것을 가져올 지 결정합니다. 이제 Relay에서 어떻게 이런 문제를 해결하는지 살펴보겠습니다.
번역하면서 생각한 것
이 글대로라면 Relay는 현재 다음과 같은 시나리오를 처리할 수 없다. (코드를 자세히 읽어보진 않았지만 아마 실제로도 안될 것 같다.)
항상 동시에 바뀌는 필드 a, b가 있다고 할 때, 다음과 같은 첫번째 쿼리를 날린다.
query {
story(id: 1) {
id
author { id, a, b }
}
}
이 때 다른 사용자(아니면 다른 기기)가 a, b의 값을 업데이트한다.
다른 화면으로 가면서 기존에 가져왔던 레코드의 a 필드만 다시 쿼리한다.
query {
story(id: 2) {
id
author { id, a } # Story 1과 같은 작성자
}
}
그러면 이제 작성자 레코드의 캐시는 a만 최신이 되고 b는 낡은 데이터가 그대로 유지된다. 그 다음에 다시 원래 화면으로 돌아오면, diff 결과 모든 데이터가 캐시에 있으므로 새로운 쿼리를 보내지 않게 되고 a와 b가 서로 다른 버전이 된다.
이 경우 가장 큰 문제는 캐시를 믿을 수가 없다는 것이다. 애플리케이션 개발자는 a, b가 항상 일관성있을 것으로 기대할텐데 그런 가정이 깨지게 된다.
가장 깔끔한 해결책은 서버에서 레코드가 변경될 때마다 달라지는 '리비전' 값을 두고, 프레임워크 수준에서 항상 쿼리에 리비전 필드를 넣어주는 것이다. 만약 기존에 알던 리비전과 다른 값이 온다면 새로운 필드만 저장하고 기존의 변경되었을지도 모르는 필드는 캐시에서 제거하면 된다.
그리고 또 한가지 부족한 점은 캐시에 유효기간이 없다는 점이다. 웹 환경에서는 한 페이지를 오래 열어두는 경우가 잘 없으니 괜찮지만 네이티브 앱이라면 너무 오래된 데이터를 보여주지 않는게 좋을 것이다. 물론 Force Fetching 기능을 쓰면 캐시된 값을 잠시 보여주는 동시에 쿼리를 날리고 결과적으로는 최신 값이 나오게 할 수 있긴 하다. 다만 완전히 캐시하는 정책과 항상 최신을 보여주는 정책의 중간 정도가 있어�서 나쁠 것은 없을 것 같다.
그러고보면 리비전, 유효기간 둘 다 HTTP 캐시의 시맨틱과도 유사하다는 생각이 든다. (각각 ETag, Expires)